저번에는 GCC와 GDB를 설치해서 메인 함수를 보는 과정을 보았는데요
이번에는 하나하나 분석을 해보도록 하겠습니다.

1차시에 봤던 GDB를 이용하여 main 함수를 보았는데요
앞에는 주소값이 나와있고, <+숫자>는 상대적인 위치를 의미 합니다.
그 옆에는 어셈블리 명령어가 나와있습니다.
하나하나 분석을 하기 위해서는 Break point를 설정을 해야 합니다
한줄 한줄 분석을 해야하기 때문이죠
그럼 break point는 어떻게 하는것이냐 -> 이거는 구글링 하세요
(gdb) b *main
이렇게 berak point 말 그대로 프로그램이 실행되다가 멈추는 지점을 설정 해주었습니다.
((b * 주소값) -> 이렇게 하면 해당 주소에 break) 또는 (b *상대적 위치)
당연히 첫번째 줄 부터 확인을 해야하니까 main 함수의 시작부분을 break 해주어야 되겠죠?

그러면 이렇게 break가 걸린것을 볼 수 있습니다.
아래의 명령어로 입력을해도 확인 할 수 있습니다.
(gdb) info b

똑같은 결과가 나온것을 확인 할 수 있습니다.
info b를 해보면 맨앞에 숫자가 보이는데 이것은 break의 번호 입니다.
(0x0000000000006d7은 해당 함수의 주소값이 됩니다.)
우리가 첫번째로 break를 걸어두었으니 1번이 되는겁니다.
아래 명령어로 break를 해제 할 수도 있습니다.
(번호를 입력하지 않는다면 모든 break를 해제합니다.)
(gdb) info b
(gdb) delete "Number"
그럼 이제 주소값이랑 break는 알겠는데...
뒤에 숫자는 뭐죠??? (맨위에 GDB 확인을 하고 오시길)
숫자는 말그대로 eip로부터 상대적 위치를 의미합니다.
그러니까 main함수는 eip로 부터 상대적 위치가 0이라는것을 의미합니다
시작 부분이니까요
그럼 모든 break를 풀고 프로그램을 실행시켜 보겠습니다.
(gdb) run

우리가 코드를 입력했던데로 결과가 제대로 나오는것을 볼 수 있습니다.

위 처럼 break를 main에 걸고나서 실행을 시키니 바로 main의 시작
부분에서 멈추는것을 볼 수 있습니다.
그러면 해당 함수에 무슨 값이 들어있는지 확인을 해보겠습니다.
x/t "메모리 주소" 2진수로 확인하기
x/o "메모리 주소" 8진수로 확인하기
x/d "메모리 주소" 10진수로 확인하기
x/u "메모리 주소" 부호없는 10진수로 확인하기
x/x "메모리 주소" 16진수로 확인하기
x/c "메모리 주소" char로 확인하기
x/f "메모리 주소" 부동소수점으로 확인하기
x/s "메모리 주소" 스트링으로 확인하기
info reg 레지스터 확인
info reg "레지스터" 특정 레지스터 확인
info break 브레이크 포인트 확인
run "args" 처음부터 실행하기
continue 멈춘 부분부터 계속 실행하기
ni 한 스탭 실행 후 멈추기
x/bx $rsp 1바이트씩 확인하기
x/hx $rsp 2바이트씩 확인하기
x/dx $rsp 4바이트씩 확인하기
x/gx $rsp 8바이트씩 확인하기
위의 명령어를 참고하여 분석을 진행하겠습니다.

break를 걸어주면 화살표 모양이 생기는데
지금 이 위치에 Break가 걸려있다는 의미가 됩니다
여기서 레지스터의 정보를 확인하여 어떤값이 들어가 있는지 보면

현재 rsp 와 rbp , rip에만 동일한 값이 들어가있는 것을 확인 할 수 있습니다.
rip는 다음에 실행할 명령어를 가리키는데 지금 현재 main 함수 즉, break를 걸어놓은 곳 입니다.
그렇다면 rsp는 지금현재 0x7ffffffee2eB라는 값이 들어가있는데 스택의 사용자 영역에
들어와 있다는 것을 의미합니다.
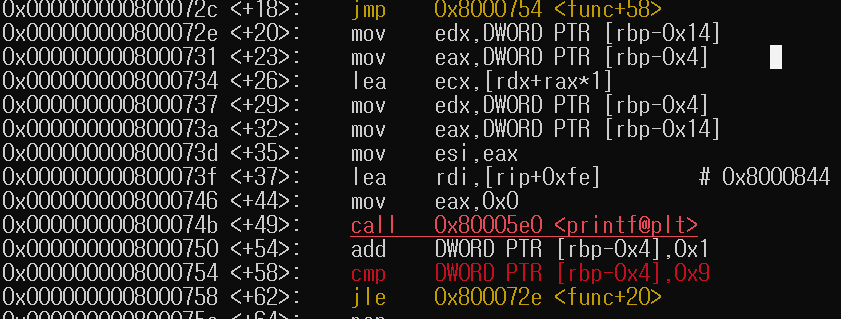
ni 명령어로 실행한다음 disass main으로 main 함수들을 확인해보면
화살표가 한칸 아래를 가리키고 있습니다. 그럼 이상태에서 rsp 값을 확인해보면 되겠죠?

아무것도 현재 push를 하고 있지 않기 때문에 rsp값은 변경되지는 않은것 같네요

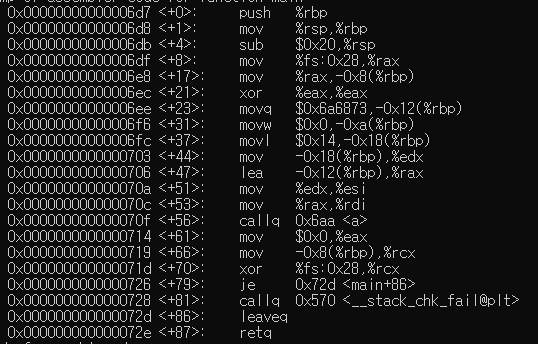
하나하나 분석을 진행하는데 우리가 코드에 작성해두었던 문자열을 확인하기 위해서
한줄 한줄 문자열로 확인을 해보았는데 shj라는 문자열이 +23의 위치에 확인이 되고 있었습니다.
대부분 스택은 4바이트 씩 쌓이니까 +27의 위치에 혹시나 하고 확인을 해봤는데
역시나 shj라는 문자열이 들어가있습니다.

계속 보던 도중에 다음과 같은 명령어가 확인이 되었는데요
딱봐도 0x14 즉 20이라는 값을 rbp-0x18이라는 공간에 mov하고 있는것을 알 수 있습니다.
그래서 여기가 age라는 함수 일 것이라고 예상을 했습니다.
그리고 다시 edx로 mov를 하고 있습니다.

그래서 +44의 위치에 info reg를 이용해서 레지스터의 값을 확인해보니까
rdx에 정상적으로 20이 들어가있네요

그러면 여기서 아까 edx에 mov를 했는데 rdx에 들어가는 이유가 무엇이냐
64비트 체제이기 때문이라고 할 수 있는데요
rdx는 기존의 32비트 체제에서 사용하던 edx의 확장판이기 때문입니다.
그러므로 굳이 8바이트를 다 쓰지 않고 4바이트만 사용하는
경우에는 rdx의 절반인 edx를 사용하고 있는 것이죠 (다른 레지스터도 똑같습니다.)
그래서 아까 shj라는 문자열을 +23의 위치에 확인하고 나서
+27에 들어가 있는 이유도 같은 이유 입니다. (4바이트씩 쌓였기 때문)

여기서 a라는 함수를 호출하고 종료하는것 같은데요 한번 확인해보겠습니다.

a라는 함수가 실행이 되고 다음으로 넘어가게 됩니다.
그러면 그 뒤 부분은 스택을 정리하고 정상적으로 프로그램이 종료가 되겠네요

이렇게 스택을 정리하고 종료가 됩니다.
그래서 요약을 하자면
이 프로그램은 name의 shj라는 문자열과 int age = 20 이라는 값을
함수 a로 call해서 실행한후 종료되는 프로그램 입니다.
이렇게 GDB를 이용해서 프로그램을 분석을 해보았습니다.
그럼 20000