저번 포스팅에서는 레지스터를 알아보았습니다.
그럼 이제 리눅스 메모리 영역과 어셈블리어, 그리고 나중에 어셈블리어가
어떻게 동작해서 프로그램을 실행하는지 알아보겠습니다.
리눅스 메모리 영역
리눅스 메모리 영역을 도식화 한건데 아래와 같습니다.

text 영역 (code 영역)
실행 가능한 기계어 코드가 위치 하는 영역
(우리가 만든 c언어가 기계어로 변환되어 해당 영역에 들어감)
data 영역
특정 값으로 초기화 된 전역 변수들이 위치하는 공간
bss 영역
초기화 되지 않은 전역 변수들이 위치하는 공간
stack 영역
함수의 인자나 함수 내부에서 선언 된 지역 변수들이 위치하는 공간
새로운 함수가 호출 될 때마다 새로운 스택 프레임(이건 나중에 설명)이 형성 됨
heap 영역
malloc, calloc 등으로 할당한 동적 메모리(heap memory)가 위치하는 공간
메모리 영역을 알아보았는데 그러면 어떻게 저장이되는지 알아보기 위해
아래의 예제 코드를 보도록 하겠습니다.
#include<stdio.h>
#include<stdlib.h>
int a = 10;
int b;
int main()
{
void * ptr = malloc(100);
int arr[100];
free(ptr);
return 0;
}
그럼 이 코드들은 어느 영역에 저장 되는지 보겠습니다.
아래와 같이 저장된다고 보면 되겠습니다.
int a = 10; //-> data 영역
int b; //-> bss 영역
int main()// -> 함수 선언 Stack 영역
{
void * ptr = malloc(100); // -> 동적 메모리 라서 heap 영역
int arr[100]; //stack 영역 -> main 함수가 stack 영역에 들어가기 때문
free(ptr);
return 0;
}
그런데 하나의 코드가 눈에 띄네요 바로 아래의 코드인데요
이 코드는 어디에 저장이 될까요?
main함수라서 stack영역? 아니면 동적메모리를 해제하는 함수라서 heap영역?
free(ptr);
설명을 드리면 main함수 안에서 변수가 선언이 되었기 때문에
stack영역에 저장이됩니다. stack영역에 저장이 되지만 free(ptr),
즉, free 함수가 가리키고 있는곳은 ptr이 저장된 heap영역이 되는 겁니다.
어셈블리어
어셈블리어 명령어들은 아래 링크를 이용하여 참고 바랍니다.
https://www.notion.so/Assembly-program-1f4cf7313d4a467fb65036f8a77644ee
아래의 예제 코드가 있는데 이렇게 동작한다고 보면 됩니다.
inc eax //eax 1 증가
dec eax //eax 1 감소
add esp 0xb //esp에 0xb를 더한 뒤 esp에 저장
sub esp 10 //esp에 10을 뺀 뒤 esp에 저장
call address //주소 값 함수 호출 및 이동
call eax //eax에 저장된 주소의 함수 호출 및 이동
우리가 이전에 리눅스 메모리 영역에 대해서 알아보았는데
핵심적인 부분은 main함수입니다.
말 그대로 코드에서 메인 즉 중심이 된다는 이야기니까요.
그럼 우리는 main함수가 저장되는 Stack 영역을 깊게 볼 필요가 있습니다.
Stack Area
메모리의 스택(stack) 영역은 함수의 호출과 관계되는
지역 변수와 매개변수가 저장되는 영역 스택 영역은 함수의 호출과 함께 할당되며,
함수의 호출이 완료되면 소멸한다.
그럼 stack이 도데체 어떻게 형성이 되고, 앞서 말했던 Stack frame이 도데체 무엇이냐
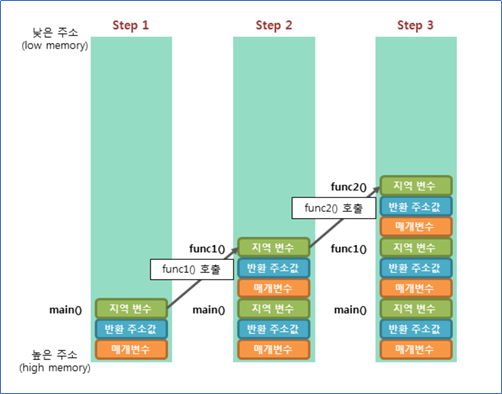
위의 그림처럼
스택 영역에 차례대로 저장되는 함수의 호출 정보를 스택 프레임(stack frame)이라고 합니다.
함수 프롤로그 : 새로운 함수 내에서 사용할 스택 프레임을 형성
함수 애필로그 : 해당 함수의 스택 프레임을 정리하고 이전 함수로 돌아가는 과정
프롤로그, 에필로그 과정 알아보기 위해서 아래 예제코드를 사용하도록 하겠습니다.
void a()
{
char arr[40];
}
int main(){
char arr[100];
int num;
a();
return 0;
}
그럼 이 코드들은 Stack 영역에 어떻게 저장이 될까요?
첫번째로 main 함수가 끝나고 복귀할 주소(return address)가 필요할거 같습니다.
두번째로 함수(여기서는 a( ))가 사용되는 주소가 필요할거 같습니다.
마지막으로 main 함수안에 사용되는 변수들이 저장될 주소가 필요할거 같습니다.
여기서 하나 주의사항은 스택은 높은주소에서 낮은 주소로 쌓인다는 점 입니다.
그러니까 우리가 보기에는 거꾸로 쌓인다고 보면 편할거 같습니다.
그럼 이것을 그림으로 나타내보면 아래와 같죠?

PUSH EIP - 함수 호출

함수 프롤로그 (Push ebp)

함수 프롤로그 (mov ebp, esp)

함수 애필로그 (mov esp, ebp)

함수 애필로그 (pop ebp)

함수 애필로그 (pop eip)

이렇게해서 리눅스의 메모리 영역과 실제로 어떻게 저장되고
어셈블리어가 어떻게 동작을 하는지에 대해서 알아보았습니다.
이것에 대한 내용을 바탕으로 1차시에 있었던 내용을 응용하여
생각해 볼 수 있겠죠? 이것으로 1주차 포스팅을 마치도록 하겠습니다.
그럼 20000~
'Theory > Pwnable' 카테고리의 다른 글
| 찬희의 Pwn 포너블 기초 3주차 1차시 homework.c (0) | 2021.09.09 |
|---|---|
| 찬희의 Pwn 포너블 기초 2주차 2차시 GDB를 사용해보자 2 (0) | 2021.08.28 |
| 찬희의 Pwn 포너블 기초 2주차 1차시 GDB를 사용해보자 1 (0) | 2021.08.28 |
| 찬희의 Pwn 포너블 기초 1주차 2차시 (0) | 2021.08.22 |
| 찬희의 Pwn 포너블 기초 1주차 1차시 (0) | 2021.08.22 |