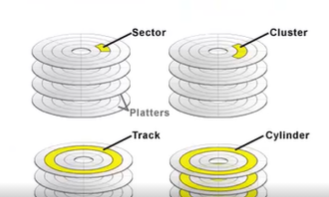
이전에 우리가 클러스터에 대해서 알아보았는데요,
조금더 깊게 들어가 보도록 하겠습니다.
Cluster
여러개의 섹터(하드디스크이 물리적 최소 단위)를 묶은 단위 입니다.
섹터 단위로 입출력을 처리하면 시간이 오래걸리기 때문에 여러개의 섹터를 한번에 묶어서 처리 합니다.
여기서 주의 할 점은 섹터는 물리적인 최소 단위를 의미하고 클러스터는 논리적인 최소 단위를 의미합니다.
그럼 클러스터 안에 여러개의 클러스터가 있을텐데 그럼 클러스터 보다 데이터의 양이 작으니끼
슬랙들이 생기게 되는데 램슬랙과 파일 슬랙이 있습니다.
램슬랙은 쉽게 말해서 하나의 섹터 안에서 (512byte) 모든 파일이 딱 맞게 떨어지지는 않을 것입니다.
물론 클러스터 단위로도 맞게 떨어지지는 않을 것 입니다.
하지만 실제로 사용되는 섹터 입니다.(일부분이 사용되기 때문)
섹터 내부에서 사용되지 않은 영역은 램슬랙
클러스터 내부에서 사용되지 않은 부분을 파일슬랙이라고 합니다.

만약에 클러스터 크기를 4096byte를 지정했을때, 100byte의 데이터를 저장하는 경우,
클러스터의 크기만큼 할당이 됩니다. 그러면 낭비가 아니야??
맞습니다.
3996byte가 낭비되지만 그럼에도 불구하고 디스크 입출력 횟수를 줄이기 위해서 클러스터 단위를 사용합니다.
4MB(4096KB)를 저장할 때 4KB크기의 클러스터를 사용하게 되면 1024번 입출력을 수행하게 되지만
4MB(4096KB)를 저장할 때 512Byte 크기의 클러스터를 사용하게 되면 8192번 수행하게 됩니다.
섹터 단위로 처리하면 이렇게 시간이 오래걸린다는 단점이 있습니다.
낭비되는 부분이 있지만 입출력의 속도가 더 중요하다고 판단을 하기 때문입니다.
그래서 여러개의 섹터를 묶어서 클러스터 단위로 관리를 하게 됩니다.
| 구분 | 장점 | 단점 |
| 클러스터 크기가 작음 | 낭비되는 영역이 적다(Slack) | 파일 정보 관리 영역이 커진다 |
| 클러스터 크기가 큼 | 클러스터 처리 부담이 적다 | 낭비되는 영역이 많다(Slack) |
이번에는 파일시스템 클러스터를 조금 더 심화적으로 알아보았는데
다음 포스팅에서는 슬랙 영역을 보도록 하겠습니다.
'Theory > Forensic' 카테고리의 다른 글
| 외전 - 디포 스토리 (Partition & Volume) (0) | 2021.10.02 |
|---|---|
| 찬희의 디포 이야기 - 파일시스템(슬랙 영역) (0) | 2021.10.02 |
| 찬희의 디포 이야기 하드디스크 구조 - 2 (0) | 2021.10.02 |
| 찬희의 디포 이야기 - 하드디스크 구조 (0) | 2021.10.02 |
| 찬희의 디포이야기 - 파일시스템 기초 (0) | 2021.10.01 |